Hashing, Hash Tables, and Binary Tree
Hashing, Hash Tables, & Binary Tree
Hello, welcome back to my blog, at this moment we going to talk about 'Hashing, Hash Tables, and Binary Tree'. What is hashing, hash tables, tree and binary tree? We are going to learn about them here.
Hashing
Hashing is an important Data Structure which is designed to use a special function called the Hash function which is used to map a given value with a particular key for faster access of elements. The efficiency of mapping depends of the efficiency of the hash function used.
Let a hash function H(x) maps the value x at the index x%10 in an Array. For example if the list of values is [11,12,13,14,15] it will be stored at positions {1,2,3,4,5} in the array or Hash table respectively.
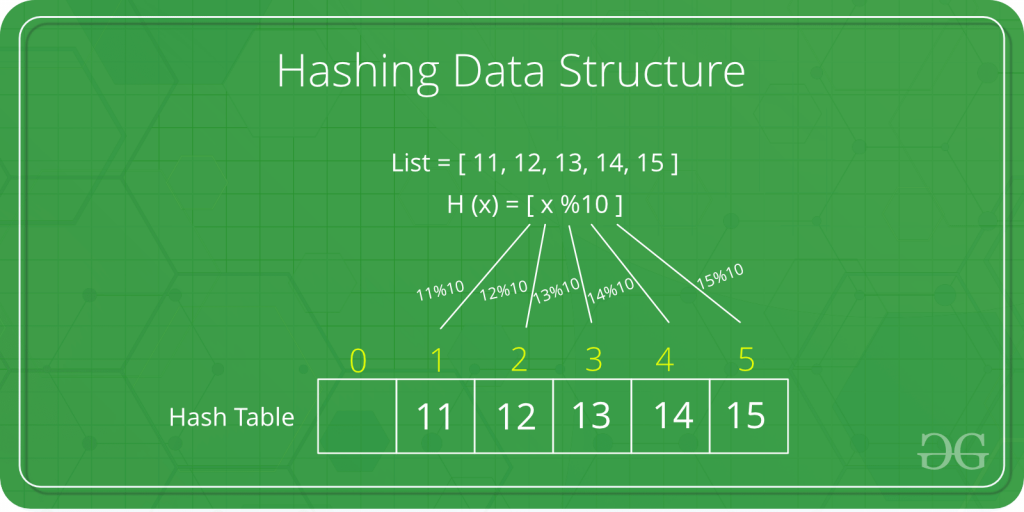
As a simple example of the using of hashing in databases, a group of people could be arranged in a database like this:
Abernathy, Sara Epperdingle, Roscoe Moore, Wilfred Smith, David (and many more sorted into alphabetical order)
Each of these names would be the key in the database for that person's data. A database search mechanism would first have to start looking character-by-character across the name for matches until it found the match (or ruled the other entries out). But if each of the names were hashed, it might be possible (depending on the number of names in the database) to generate a unique four-digit key for each name. For example:
7864 Abernathy, Sara 9802 Epperdingle, Roscoe 1990 Moore, Wilfred 8822 Smith, David (and so forth)
A search for any name would first consist of computing the hash value (using the same hash function used to store the item) and then comparing for a match using that value. It would, in general, be much faster to find a match across four digits, each having only 10 possibilities, than across an unpredictable value length where each character had 26 possibilities.
The hash function is used to index the original value or key and then used later each time the data associated with the value or key is to be retrieved. Thus, hashing is always a one-way operation. There's no need to "reverse engineer" the hash function by analyzing the hashed values. In fact, the ideal hash function can't be derived by such analysis. A good hash function also should not produce the same hash value from two different inputs. If it does, this is known as a collision. A hash function that offers an extremely low risk of collision may be considered acceptable.
Here are some relatively simple hash functions that have been used:
- Division-remainder method: The size of the number of items in the table is estimated. That number is then used as a divisor into each original value or key to extract a quotient and a remainder. The remainder is the hashed value. (Since this method is liable to produce a number of collisions, any search mechanism would have to be able to recognize a collision and offer an alternate search mechanism.)
- Folding method: This method divides the original value (digits in this case) into several parts, adds the parts together, and then uses the last four digits (or some other arbitrary number of digits that will work ) as the hashed value or key.
- Radix transformation method: Where the value or key is digital, the number base (or radix) can be changed resulting in a different sequence of digits. (For example, a decimal numbered key could be transformed into a hexadecimal numbered key.) High-order digits could be discarded to fit a hash value of uniform length.
- Digit rearrangement method: This is simply taking part of the original value or key such as digits in positions 3 through 6, reversing their order, and then using that sequence of digits as the hash value or key.
Hash Tables
Hash Table is a data structure which stores data in an associative manner. In hash table, the data is stored in an array format where each data value has its own unique index value. Access of data becomes very fast, if we know the index of the desired data.
Basic Operations
Following are the basic primary operations of a hash table.
- Search − Searches an element in a hash table
- Insert − inserts an element in a hash table.
- delete − Deletes an element from a hash table.
DataItem
Define a data item having some data and key, based on which the search is to be conducted in a hash table.

Hash Method
Define a hashing method to compute the hash code of the key of the data item.

Search Operation
Whenever an element is to be searched, compute the hash code of the key passed and locate the element using that hash code as index in the array. Use linear probing to get the element ahead if the element is not found at the computed hash code.
Example

Insert Operation
Whenever an element is to be inserted, compute the hash code of the key passed and locate the index using that hash code as an index in the array. Use linear probing for empty location, if an element is found at the computed hash code.
Example

Delete Operation
Whenever an element is to be deleted, compute the hash code of the key passed and locate the index using that hash code as an index in the array. Use linear probing to get the element ahead if an element is not found at the computed hash code. When found, store a dummy item there to keep the performance of the hash table intact.
Example

Binary Tree
A tree whose elements have at most 2 children is called a binary tree. Since each element in a binary tree can have only 2 children, we typically name them the left and right child.
Binary tree also known as B-tree.
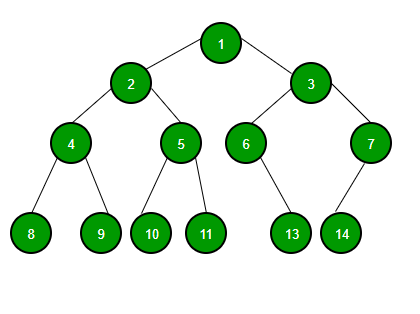
A Binary Tree node contains following parts.
- Data
- Pointer to left child
- Pointer to right child
Example of Binary Tree Node

Search in B-Tree
To search a given key in Binary Search Tree, we first compare it with root, if the key is present at root, we return root. If key is greater than root’s key, we recur for right subtree of root node. Otherwise we recur for left subtree.

Insert in B-Tree
A new key is always inserted at leaf. We start searching a key from root till we hit a leaf node. Once a leaf node is found, the new node is added as a child of the leaf node.

Source :
1. https://www.geeksforgeeks.org/hashing-data-structure/
2. https://searchsqlserver.techtarget.com/definition/hashing
3. https://www.tutorialspoint.com/data_structures_algorithms/hash_table_program_in_c.htm
4. https://www.tutorialspoint.com/data_structures_algorithms/hash_data_structure.htm
5. https://www.geeksforgeeks.org/binary-tree-data-structure/
6. https://www.geeksforgeeks.org/binary-tree-set-1-introduction/
7. https://www.geeksforgeeks.org/binary-search-tree-set-1-search-and-insertion/
2. https://searchsqlserver.techtarget.com/definition/hashing
3. https://www.tutorialspoint.com/data_structures_algorithms/hash_table_program_in_c.htm
4. https://www.tutorialspoint.com/data_structures_algorithms/hash_data_structure.htm
5. https://www.geeksforgeeks.org/binary-tree-data-structure/
6. https://www.geeksforgeeks.org/binary-tree-set-1-introduction/
7. https://www.geeksforgeeks.org/binary-search-tree-set-1-search-and-insertion/



Komentar
Posting Komentar